Unicode Security Guide
1) Home Page
2) Background
Unicode Security Guide
Visual Spoofing
While Unicode has provided an incredible framework for storing, transmitting, and presenting information in many of our world’s native languages, it has also enabled attack vectors for phishing and word filters. Commonly referred to as ‘visual spoofing’ these attack vectors leverage characters from various languages that are visually identical to letters in another language.
To a human reader, some of the following letters are indistinguishable from one another while others closely resemble one another:
AΑ А ᗅ ᗋ ᴀ A
To a computer system however, each of these letters has very different meaning. The underlying bits that represent each letter are different from one to the next.
Table of Contents
Prior Research
One of the most well-known attacks to exploit visual spoofing was the Paypal.com IDN spoof of 2005. Setup to demonstrate the power of these attack vectors, Eric Johanson and The Schmoo Group successfully used a www.paypal.com lookalike domain name to fool visitors into providing personal information. The advisory references original research from 2002 by Evgeniy Gabrilovich and Alex Gontmakher at the Israel Institute of Technology. Their original paper described an attack using Microsoft.com as an example.
Viktor Krammer, author of the Quero Toolbar for Internet Explorer, also presented additional research on these attack vectors and detection mechanisms in his 2006 presentation. Additionally, the Unicode Consortium has been active at raising awareness of these issues in its security papers, and in providing recommended solutions.
Summary of Vectors
The phenomena of ‘visual spoofing’ may be malicious and deliberate or benign and accidental. There have been cases where a choice of font displayed a sequence of characters in an unintended way, just as there have been cases where Unicode characters did not display properly. The following list attempts to capture the major vectors:
Non-Unicode lookalikes
Simple characters or character combinations can look like something else. For example, the letters “r” and “n” together can look like the letter “m”. E.g. “rn”. Also, the number “0” can look like the letter “O”, the number “1” can look like the letter “l”, and so on.
Unicode Confusables
The Unicode Confusables are discussed in detail later in this document. In short, these are the diverse array of non-ASCII Unicode characters which are easily confused with characters across languages.
__ The Invisibles__
Discussed later in this document, these are characters which have no visual appearance and minimal spacing if any spacing at all. Hence, they are visually non-existant.
Problematic font-rendering
Fonts are ultimately responsible for the visual display of characters, and can sometimes render glyphs confusingly, or as empty white space. There are numerous examples of this, just one of which is described below:
| Character sequence | Should appear as | Might appear as |
| U+00B7 U+0041 U+0338 | A̸ | A/ |
Manipulating combining-marks
Combining marks can be stacked or re-ordered in a myriad of ways. Consider the following table which illustrates just one way that combining marks can be stacked (using one directly after another). The table also shows an example of how combining marks can be re-ordered in a different sequence, but still have the same visual appearance.
| Character sequence | Appears as |
| U+006F U+0304 | ō |
| U+006F U+0304 U+0304 | ō̄ |
| U+006F U+0336 U+0335 | o̶̵ |
| U+006F U+0335 U+0336 | o̵̶ |
Bidi and syntax spoofing Another interesting vector uses the ‘bidirectional’ properties of certain characters, also known as ‘bidi’.
Attack Scenarios
A variety of scenarios exist where visual spoofing may be used to attack and exploit people. This section looks at a few.
Spoofing Domain Names
Domain names represent an interesting attack vector because their mere visual appearance inspires trust in a brand. The following image represents what visually appear as two identical domain names, however, the second contains the U+0261 LATIN SMALL LETTER SCRIPT G.

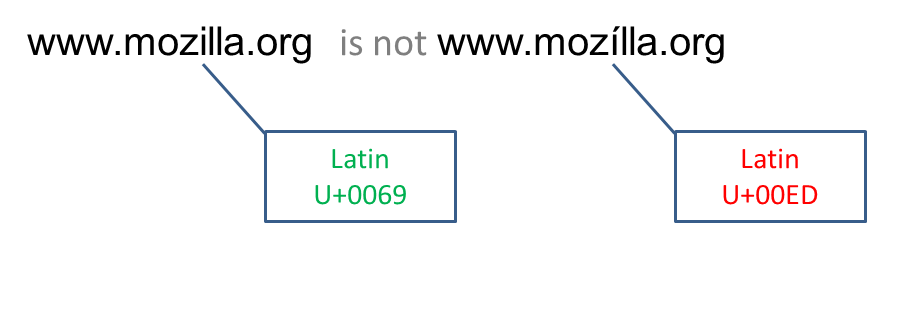
The tricky part about presenting domain names is that they often get simply a glance, if any look at all. The following image represents two domain names which might be visually similar ‘enough’ to fool someone, yet not identical.
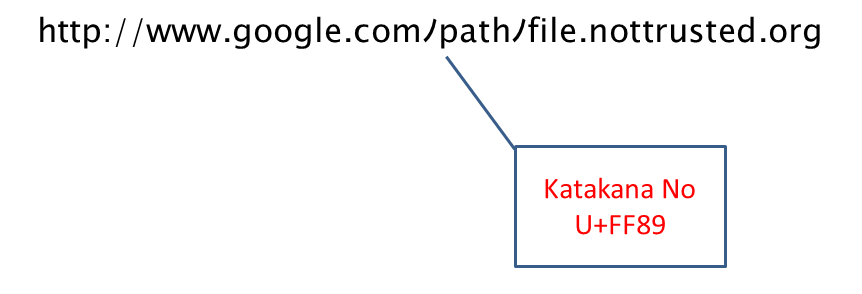
Finally, characters that appear to be syntactic elements, such as U+FF89 HALFWIDTH KATAKANA LETTER NO which resembles the forward-slash path-separator, can be troublesome. In the following image, this character is used in the subdomain label of a domain name, but appears to be a path-separator.
Fraudulent Vanity URL’s
A social networking service wants to allow vanity URL’s to be registered using international characters such as www.foo.bar/фу but perceives too great a risk from the variety of ways that the URL could be subject to visual fraud and confusion. Because Unicode characters are well-supported in the path portion of a browser’s URL display, a well-crafted vanity URL could easily fool victims and be the landing page for a phishing attack. In fact, it’s often unnecessary to use Unicode - in some cases, the number one “1” can appear as the letter “l”, and in certain fonts the sequence “rn” can appear as the letter “m”.
Bypassing Profanity Filters
An email or forum system needs to prevent violent and profane words from being used. It’s well-known that there are trivial ways to bypass such filters, including using spacing and punctuation between letters in a word (e.g. c_r_a_p), or slight misspellings which give the same effect (e.g. crrap), to name just a couple. There’s also the possibility of using confusable characters which have no visual side-affect (e.g. crap) written entirely in another script (or a mix of scripts).
Spoofing User Interface Dialogs
Security decisions are often presented to end users in the form of dialog boxes consisting in part of user-supplied input. For example:
- When a user downloads a file through a Web browser, they’re asked to confirm their decision, often with the filename as a part of the dialog’s content.
- When a user tries to launch an untrusted application they may also be presented with a dialog box asking for confirmation.
- A social networking site may ask its users for confirmation before redirecting them to an off-site URL, often with the URL making up the dialog’s content.
In any of these cases, a clever attack may use special BIDI or other characters that reverse the direction of text, or otherwise manipulate the text in a way that may confuse or fool the end users.
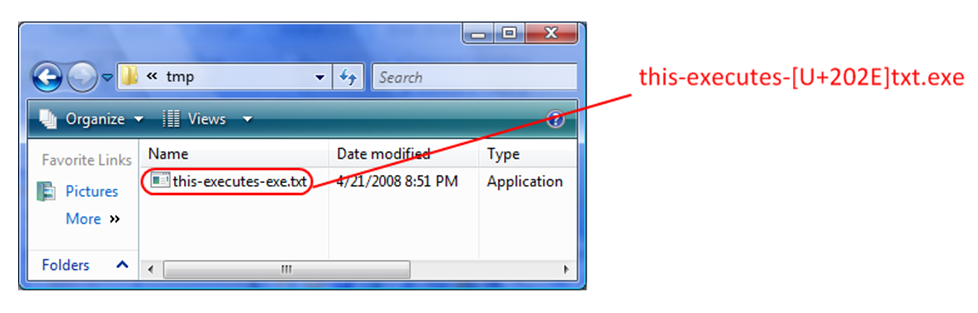
Consider the following image which shows the Windows Explorer program. What appears to be a plain text file ending in the “.txt” file extension, is actually an executable file ending in the “.exe” extension. Fortunately, Windows Explorer recognizes the true file type, which it has listed as “Application”.
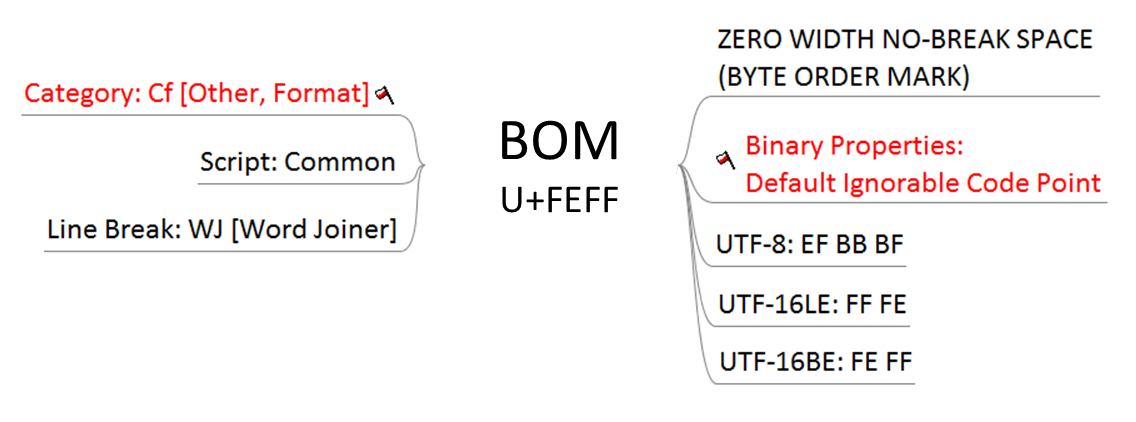
In another example, the U+FEFF ZERO WIDTH NO-BREAK SPACE character, also known as the Byte-Order Mark, or BOM, acts as an ‘invisible’ character.
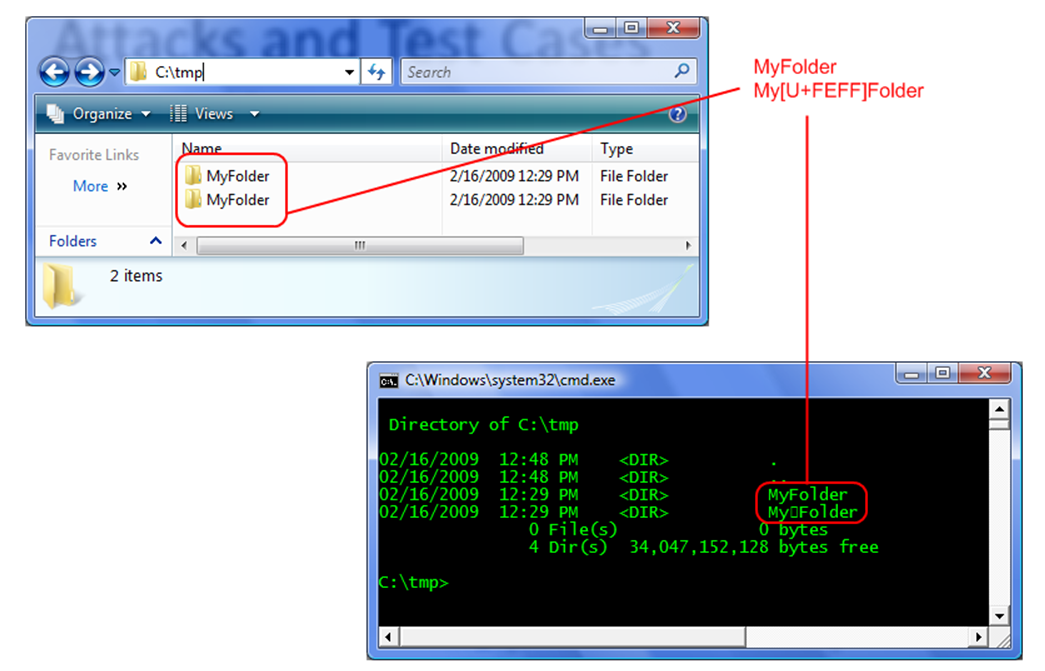
Invisible characters present their own interesting dynamics and applications. As seen in the image above, Windows Explorer presents what appears to be two folders with identical names, whereas a default command prompt does not properly display the BOM, and so presents it as an empty box.
Malvertisements
Advertising network’s often need to protect brand name trademarks from being registered or used by anyone other than their owner. This threat might be mitigated through filters, human editorial inspection, or a combination of the two. An attacker could place an malicious phishing ad that bypasses trademark filters by using confusable characters. For example “Download Microsoft Windows 8 Service Pack 1 here” where the trademarked name ‘Microsoft Windows’ was crafted using non-English script, or even using invisible characters.
Forging Internationalized Email
Email addresses and the SMTP protocol has long been confined to ASCII, however, standards work through the IETF was concluded in 2013 by the Email Address Internationalization Working Group. The EAI effort delivered documentation for integrating UTF-8 into the core email protocols, as well as advice to EAI deployment in client and server software. In preparing for the transition, email client engineers and designers will need to anticipate and handle the case of visually identical email addresses, among other issues. If left unhandled, then end users could easily be fooled. Digital certificates would provide a good mechanism for proving authenticity of a message; however such certificates also support Unicode and are vulnerable to the exact same attacks.
Defensive Options
All does not seem lost. While
The Confusables
Throughout Unicode, the characters that visually resemble one another are referred to as the confusables. The Unicode Consortium has documented this phenomena in both Technical Report 36 and TR 39.
It is TR 39 specifically which provides links to the data files comprising the confusables, such as confusables.txt which provides a mapping for visual confusables.
The Unicode Consortium has also provided Unicode Utilities: Confusables which takes an input string and produces visually confusable strings generated using the prior mentioned data files.
Single-Script Confusables
Mixed-Script Confusables
Whole-Script Confusables
The Invisibles