Unicode Security Guide
1) Home Page
2) Background
Unicode Security Guide
Character Transformations
This section attempts to explore the various ways in which characters and strings can be transformed by software processes. Such transformations are not vulnerabilities necessarily, but could be exploited by clever attackers.
As an example, consider an attacker trying to inject script (i.e. cross-site scripting, or XSS attack) into a Web-application which utilizes a defensive input filter. The attacker finds that the application performs a lowercase operation on the input after filtering, and by injecting special characters they can exploit that behavior. That is, the string “script” is prevented by the filter, but the string “scrİpt” is allowed.
Table of Contents
- Round Trip
- Best Fit Mappings
- Charset Transcoding and Character Mappings
- Normalization
- Canonicalization of Non-Shortest Form UTF-8
- Over-Consumption
- Handling the Unexpected
- Upper and Lower Casing
- Buffer Overflows
- Controlling Syntax
- Charset Mismatch
Round-trip Conversions: A Common Pattern
In practice, globalized software must be capable of handling many different character sets, and converting data between them. The process for supporting this requirement can generally look like the following:
- Accept data from any character set, e.g. Unicode, shift_jis, ISO-8859-1.
- Transform, or convert, data to Unicode for processing and storage.
- Transform data to original or other character set for output and display.
In this pattern, Unicode is used as the broker. With support for such a large character repertoire, Unicode will often have a character mapping for both sides of this transaction. To illustrate this, consider the following Web application transaction.
- An application end-user inputs their full name using characters encoded from the shift_jis character set.
- Before storing in the database, the application converts the user-input to Unicode’s UTF-8 format.
- When visiting the Web page, the user’s full name will be returned in UTF-8 format, unless other conditions cause the data to be returned in a different encoding. Such conditions may be based on the Web application’s configuration or the user’s Web browser language and encoding settings. Under these types of conditions, the Web application will convert the data to the requested encoding.
The round-trip conversions illustrated here can lead to numerous issues that will be further discussed. While it serves as a good example, this isn’t the only case where such issues can arise.
Best-fit Mappings
The “best-fit” phenomena occurs when a character X gets transformed to an entirely different character Y. This can occur for reasons such as:
- A framework API transforms input to a different character encoding by default.
- Data is marshalled from a wide string type (multi-byte character representation) such as UTF-16, to a non-wide string (single-byte character representation) such as US-ASCII.
- Character X in the source encoding doesn’t exist in the destination encoding, so the software attempts to find a ‘best-fit’ match.
In general, best-fit mappings occur when characters are transcoded between Unicode and another encoding. It’s often the case that the source encoding is Unicode and the destination is another charset such as shift_jis, however, it could happen in reverse as well. Best-fit mappings are different than character set transcoding which is discussed in another section of this guide.
Software vulnerabilities may arise when best-fit mappings occur. To name a few:
- Best-fit mappings are often not reversible, so data is irrevocably lost. For example, a common best-fit operation would transform a U+FF1C FULLWIDTH LESS-THAN SIGN < to the U+003C LESS-THAN SIGN, or the ASCII < used in HTML. Once converted down to the ASCII <, there’s no reliable way to convert back to the FULLWIDTH source.
- Characters can be manipulated to bypass string handling filters, such as cross-site scripting (XSS) filters, WAF’s, and IDS devices.
- Characters can be manipulated to abuse logic in software. Such as when the characters can be used to access files on the file system. In this case, a best-fit mapping to characters such as ../ or file:// could be damaging.
For example, consider a Web-application that’s implemented a filter to prevent XSS (cross-site scripting) attacks. The filter attempts to block most dangerous characters, and operates at an outermost layer in the application. The implementation might look like:
- An input validation filter rejects characters such as <, >, ‘, and “ in a Web-application accepting UTF-8 encoded text.
- An attacker sends in a U+FF1C FULLWIDTH LESS-THAN SIGN < in place of the ASCII <.
- The attacker’s input looks like: <script>
- After passing through the XSS filter unchanged, the input moves deeper into the application.
- Another API, perhaps at the data access layer, is configured to use a different character set such as windows-1252.
- On receiving the input, a data access layer converts the multi-byte UTF-8 text to the single-byte windows-1252 code page, forcing a best-fit conversion to the dangerous characters the original XSS filter was trying to block.
- The attacker’s input successfully persists to the database.
Shawn Steele describes the security issues well on his blog, it’s a highly recommended short read for the level of coverage he provides regarding Microsoft’s API’s:
Best Fit in WideCharToMultiByte and System.Text.Encoding Should be Avoided. Windows and the .Net Framework have the concept of “best-fit” behavior for code pages and encodings. Best fit can be interesting, but often its not a good idea. In WideCharToMultiByte() this behavior is controlled by a WC_NO_BEST_FIT_CHARS flag. In .Net you can use the EncoderFallback to control whether or not to get Best Fit behavior. Unfortunately in both cases best fit is the default behavior. In Microsoft .Net 2.0 best fit is also slower.
As a software engineer, it’s important to understand the API’s being used directly, and in some cases indirectly (by other processing on the stack). The following table of common library API’s lists known behaviors:
| Library | API | Best-fit default | Can override | Guidance |
| .NET 2.0 | System.Text.Encoding | Yes | Yes | Specify EncoderReplacementFallback in the Encoding constructor. |
| .NET 3.0 | System.Text.Encoding | Yes | Yes | Specify EncoderReplacementFallback in the Encoding constructor. |
| .NET 3.0 | DllImport | Yes | Yes | To properly and more safely deal with this, you can use the MarshallAsAttribute class to specify a LPWStr type instead of a LPStr. [MarshalAs(UnmanagedType.LPWStr)] |
| Win32 | WideCharToMultiByte | Yes | Yes | Set the WC_NO_BEST_FIT_CHARS flag. |
| Java | TBD | ... | ||
| ICU | TBD | ... |
Another important note Shawn Steel tells us on his blog is that Microsoft does not intend to maintain the best-fit mappings. For these and other security reasons it’s a good idea to avoid best-fit type of behavior.
The following table lists test cases to run from a black-box, external perspective. By interpreting the output/rendered data, a tester can determine if a best-fit conversion may be happening. Note that the mapping tables for best-fit conversions are numerous and large, leading to a nearly insurmountable number of permutations. To top it off, the best-fit behavior varies between vendors, making for an inconsistent playing field that does not lend well to automation. For this reason, focus here will be on data that is known to either normalize or best-fit. The table below is not comprehensive by any means, and is only being provided with the understanding that something is better than nothing.
| Target char | Target code point | Test code point | Name |
| o | \u006F | \u2134 | SCRIPT SMALL O |
| o | \u006F | \u014D | LATIN SMALL LETTER O WITH MACRON |
| s | \u0073 | \u017F | LATIN SMALL LETTER LONG S |
| I | \u0049 | \u0131 | LATIN SMALL LETTER DOTLESS I |
| i | \u0069 | \u0129 | LATIN SMALL LETTER I WITH TILDE |
| K | \u004B | \u212A | KELVIN SIGN |
| k | \u006B | \u0137 | LATIN SMALL LETTER K WITH CEDILLA |
| A | \u0041 | \uFF21 | FULLWIDTH LATIN CAPITAL LETTER A |
| a | \u0061 | \u03B1 | GREEK SMALL LETTER ALPHA |
| " | \u0022 | \u02BA | MODIFIER LETTER DOUBLE PRIME |
| " | \u0022 | \u030E | COMBINING DOUBLE VERTICAL LINE ABOVE |
| " | \u0027 | \uFF02 | FULLWIDTH QUOTATION MARK |
| ' | \u0027 | \u02B9 | MODIFIER LETTER PRIME |
| ' | \u0027 | \u030D | COMBINING VERTICAL LINE ABOVE |
| ' | \u0027 | \uFF07 | FULLWIDTH APOSTROPHE |
| < | \u003C | \uFF1C | FULLWIDTH LESS-THAN SIGN |
| < | \u003C | \uFE64 | SMALL LESS-THAN SIGN |
| < | \u003C | \u2329 | LEFT-POINTING ANGLE BRACKET |
| < | \u003C | \u3008 | LEFT ANGLE BRACKET |
| < | \u003C | \u00AB | LEFT-POINTING DOUBLE ANGLE QUOTATION MARK |
| > | \u003E | \u00BB | RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK |
| > | \u003E | \u3009 | RIGHT ANGLE BRACKET |
| > | \u003E | \u232A | RIGHT-POINTING ANGLE BRACKET |
| > | \u003E | \uFE65 | SMALL GREATER-THAN SIGN |
| > | \u003E | \uFF1E | FULLWIDTH GREATER-THAN SIGN |
| : | \u003A | \u2236 | RATIO |
| : | \u003A | \u0589 | ARMENIAN FULL STOP |
| : | \u003A | \uFE13 | PRESENTATION FORM FOR VERTICAL COLON |
| : | \u003A | \uFE55 | SMALL COLON |
| : | \u003A | \uFF1A | FULLWIDTH COLON |
These test cases are largely derived from the public best-fit mappings provided by the Unicode Consortium. These are provided to software vendors but do not necessarily they were implemented as documented. In fact, any software vendor such as Microsoft, IBM, Oracle, can implement these mappings as they desire.
Charset Transcoding and Character Mappings
Sometimes characters and strings are transcoded from a source character set into a destination character set. On the surface this phenomena may seem similar to best-fit mappings, but the process is quite different. In general, when software transcodes data from source charset X to destination charset Y, it follows either a data-driven mapping table or an algorithmic formula.
For the most part this process is data-driven. While these tables are standardized somewhere there may be differences between vendors. ICU maintains a list of its character set mapping tables online. Also, ICU’s Converter Explorer tool lets you browse the maintained charset mapping tables.
Data may be transcoded directly from a source charset to a destination charset, however it’s also common to use Unicode as the broker. In the latter case the software will first transcode the source charset to Unicode, and from there to the destination charset. Some vendors such as Microsoft are known to leverage the Private Use Area (PUA) when transcoding to Unicode, when a direct mapping cannot be found or when a source byte sequence is invalid or illegal. It’s important to be aware of a few pitfalls during the transcoding process.
- When data is transcoded to the PUA, converting it again from the PUA may have unexpected consequences.
- Data can change length, particularly if transcoding to/from a single-byte charset leads to a multi-byte character in the other charset.
As a software engineer building a mechanism for transcoding data between charsets, it’s important to understand these pitfalls and handle these unexpected cases gracefully.
Software vulnerabilities can arise through charset transcodings. To name a few:
- Transcoding data is not always reversible, so data can be irrevocably lost.
- Characters can be manipulated to bypass string handling filters, such as cross-site scripting (XSS) filters, WAF’s, and IDS devices.
- Characters can be manipulated to abuse logic in software. For example, characters transcoded into ../ or file:// would prove detrimental in file handling operations.
Normalization
In Unicode, Normalization of characters and strings follows a specification defined in the Unicode Standard Annex #15: Unicode Normalization Forms. The details of Normalization are not for the faint of heart and will not be discussed in this guide. For engineers and testers, it’s at least important to understand that there are four Normalization forms defined:
- NFC - Canonical Decomposition
- NFD - Canonical Decomposition, followed by Canonical Composition
- NFKC - Compatibility Decomposition
- NFKD - Compatibility Decomposition,followed by Canonical Composition
When testing for security vulnerabilities, we’re often most interested in the compatibility decomposition forms (NFKC, NFKD), but occassionally the canonical decomposition forms will produce interesting transformations as well. Cases where characters, and sequences of characters, transform into something different than the original source, might be used to bypass filters or produce other exploits. Consider the following image, which depicts the result of normalizing with either NFKC or NFKD for the character U+FE64 SMALL LESS-THAN SIGN.

In the above example, the character U+FE64 will transform into U+003C, which might lead to security vulnerability in HTML applications. Consider the next example which shows the result of either NFD or NFKD decomposition applied to the “Turkish I” character U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE.
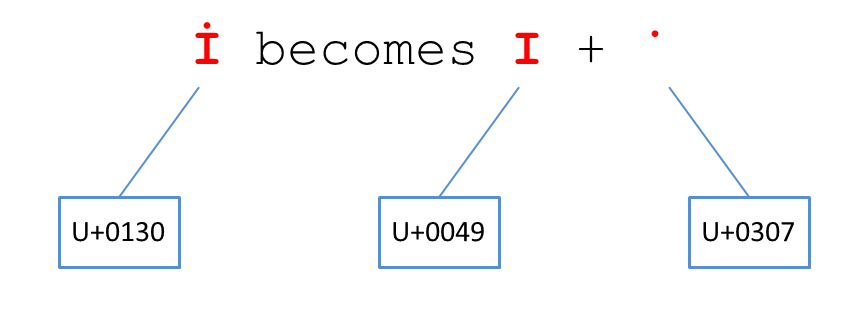
As a software engineer, it becomes evident that Unicode normalization plays an important role, and that it is not always an explicit choice. Often times normalization is applied implicitly by the underlying framework, platform, or Web browser. It’s important to understand the API’s being used directly, and in some cases indirectly (by other processing on the stack).
Normalization Defaults in Common Libraries
The following table of common library API’s lists known behaviors:
| Library | API | Default | Can override | Notes |
| .NET | System.Text.Encoding | NFC | Yes | |
| Win32 | ||||
| Java | ||||
| ICU | ||||
| Ruby | ||||
| Python | ||||
| PHP | ||||
| Perl | ||||
| JavaScript | String.prototype.normalize() | NFC | Yes | MDN |
Normalization in Web Browser URLs
The following table captures how Web browsers normalize URLs. Differences in normalization and character transformations can lead to incompatibility as well as security vulnerability. source
| Description | MSIE 9 | FF 5.0 | Chrome 12 | Safari 5 | Opera 11.5 |
| Applies normalization in the path | No | No | No | Yes - NFC | No |
| Applies normalization in the query | No | No | No | Yes - NFC | No |
| Applies normalization in the fragment | No | No | Yes - NFC | Yes - NFC | No |
Normalization Test Cases
The following table lists test cases to run from a black-box, external perspective. By interpreting the output/rendered data, a tester can determine if a normalization transformation may be happening.
| Target char | Target code point | Test code point | Name |
| o | \u006F | \u2134 | SCRIPT SMALL O |
| s | \u0073 | \u017F | LATIN SMALL LETTER LONG S |
| K | \u004B | \u212A | KELVIN SIGN |
| A | \u0041 | \uFF21 | FULLWIDTH LATIN CAPITAL LETTER A |
| " | \u0027 | \uFF02 | FULLWIDTH QUOTATION MARK |
| ' | \u0027 | \uFF07 | FULLWIDTH APOSTROPHE |
| < | \u003C | \uFF1C | FULLWIDTH LESS-THAN SIGN |
| < | \u003C | \uFE64 | SMALL LESS-THAN SIGN |
| > | \u003E | \uFE65 | SMALL GREATER-THAN SIGN |
| > | \u003E | \uFF1E | FULLWIDTH GREATER-THAN SIGN |
| : | \u003A | \uFE13 | PRESENTATION FORM FOR VERTICAL COLON |
| : | \u003A | \uFE55 | SMALL COLON |
| : | \u003A | \uFF1A | FULLWIDTH COLON |
TODO If you’ve determined that input is being normalized but need different characters to exploit the logic, you may use the accompanying test case database.
Canonicalization of Non-Shortest Form UTF-8
The UTF-8 encoding algorithm allows for a single code point to be represented in multiple ways. That is, while the Latin letter ‘A’ is normally represented using the byte 0x41 in UTF-8, it’s non-shortest form, or overlong, encoding would be any of the following:
- 0xC1 0x81
- 0xE0 0x81 0x81
- 0xF0 0x80 0x81 0x81
- etc…
Earlier versions of the Unicode Standard applied Postel’s law, or, the robustness principle of ‘be conservative in what you do, be liberal in what you accept from others.’ While the ‘generation’ of non-shortest form UTF-8 was forbidden, the ‘interpretation’ of was allowed. That changed with Unicode Standard version 3.0, when the requirement changed to prohibit both interpretation and generation. In fact, both the ‘generation’ and ‘interpretation’ of non-shortest form UTF-8 are currently prohibited by the standard, with one exception - that ‘interpretation’ only applies to the Basic Multilingual Plane (BMP) code points between U+0000 and U+FFFF. In terms of the common security vulnerabilities discussed in this document, that exception has no bearing, as the ASCII range of characters are not exempt.
Given the history of security vulnerabilities around overlong UTF-8, many frameworks have defaulted to a more secure position of disallowing these forms to be both generated and interpreted. However, it seems that some software still interprets non-shortest form UTF-8 for BMP characters, including ASCII. A common pattern in software follows:
Process A performs security checks, but does not check for non-shortest forms.
Process B accepts the byte sequence from process A, and transforms it into UTF-16 while interpreting non-shortest forms.
The UTF-16 text may then contain characters that should have been filtered out by process A. source
The overlong form of UTF-8 byte sequences is currently considered an illegal byte sequence. It’s therefore a good test case to attempt in software such as Web applications, browsers, and databases.
Some notes about canonicalization and UTF-8 encoded data.
- The ASCII range (0x00 to 0x7F) is preserved in UTF-8.
- UTF-8 can encode any Unicode character U+000000 through U+10FFFF using any number of bytes, thus leading to the non-shortest form problem.
- The Unicode standard (3.0 and later) requires that a code point be serializd in UTF-8 using a byte sequence of one to four bytes in length. The Corrigendum #1: UTF-8 Shortest Form introduced this conformance requirement.
Non-shortest form UTF-8 has been the vector for critical vulnerabilities in the past. From the Microsoft IIS 4.0 and 5.0 directory traversal vulnerability of 2000, which was rediscovered in the product’s WebDAV component in 2009.
Some of the common security vulnerabilities that use non-shortest form UTF-8 as an attack vector include:
- Directory/folder traversal.
- Bypassing folder and file access filters.
- Bypassing HTML and XSS filters.
- Bypassing WAF and NID’s type devices.
As a developer trying to protect against this, it becomes important to understand the API’s being used directly, and in some cases indirectly (by other processing on the stack). The following table of common library API’s lists known behaviors:
| Library | API | Allows non-shortest UTF8 | Can override | Notes |
| .NET 2.0 | System.Text.Encoding | |||
| .NET 3.0 | System.Text.Encoding | |||
| ICU | System.Text.Encoding |
As a tester/bug hunter looking for the vulnerabilities, the following table lists test cases to run from a black-box, external perspective. The data in this table presents the first few non-shortest forms (NSF) UTF-8 as URL encoded data %NN. If you need raw bytes instead, these same hex values apply. All of the target chars in the first column are ASCII.
| Target | NSF 1 | NSF 2 | NSF 3 | Notes | |
| A | %C1%81 | %E0%81%81 | %F0%80%81%81 | Latin A useful as a base test case. | |
| " | %C0%A2 | %E0%80%A2 | %F0%80%80%A2 | Double quote | |
| ' | %C0%A7 | %E0%80%A7 | %F0%80%80%A7 | Single quote | |
| < |
%C0%BC | %E0%80%BC | %F0%80%80%BC | Less-than sign | |
| > |
%C0%BE | %E0%80%BE | %F0%80%80%BE | Greater-than sign | |
| . | %C0%AE | %E0%80%AE | %F0%80%80%AE | Full stop | |
| / | %C0%AF | %E0%80%AF | %F0%80%80%AF | Solidus | |
| \ | %C1%9C | %E0%81%9C | %F0%80%81%9C | Reverse solidus |
Over-consumption
The Unicode Transformation Formats (e.g. UTF-8 and UTF-16) serialize code points into legal, or well-formed, byte sequences, also called code units. For example, consider the following code points and their corresponding well-formed code units in UTF-8 format.
| Code point | Description | UTF-8 byte sequence |
| U+0041 | LATIN CAPITAL LETTER A | 0x41 |
| U+FF21 | FULLWIDTH LATIN CAPITAL LETTER A | 0xEC 0xBC 0xA1 |
| U+00C0 | LATIN CAPITAL LETTER A WITH GRAVE | 0xC3 0x80 |
And following are the same code points in their corresponding well-formed UTF-16 (little endian) format.
| Code point | Description | UTF-16LE byte sequence |
| U+0041 | LATIN CAPITAL LETTER A | 0x00 0x41 |
| U+FF21 | FULLWIDTH LATIN CAPITAL LETTER A | 0xFF 0x21 |
| U+00C0 | LATIN CAPITAL LETTER A WITH GRAVE | 0x00 0xC0 |
Well-formed and Ill-formed Byte Sequences
Consider a UTF-8 decoder consuming a stream of data from a file. It encounters a well-formed byte sequence like:
<41 C3 80 41>
This sequence is made up of three well-formed sub-sequences. First is the <41>, second is the <C3 80>, and third is the <41>. The second subsequence <C3 80> is a two-byte sequence. The lead byte C3 indicates a two-byte sequence, and the trailing byte 80 is a valid trailing byte. The table below indicates these relationahips. Now consider that the UTF-8 decoder encounters an ill-formed byte sequence:
<41 C2 C3 80 41>
Taken apart, there are three minimally well-formed subsequences <41>, <C3 80>, and <41>. However, the <C2> is ill-formed because it doesn’t have a valid trailing byte, which would be required per the table below.
| Code point | First byte | Second byte | Third byte | Fourth byte |
| U+0000..U+007F | 00..7F | |||
| U+0080..U+07FF | C2..DF | 80..BF | ||
| U+0800..U+0FFF | E0 | A0..BF | 80..BF | |
| U+1000..U+CFFF | E1..EC | 80..BF | 80..BF | |
| U+D000..U+D7FF | ED | 80..9F | 80..BF | |
| U+E000..U+FFFF | EE..EF | 80..BF | 80..BF | |
| U+10000..U+3FFFF | F0 | 90..BF | 80..BF | 80..BF |
| U+40000..U+FFFFF | F1..F3 | 80..BF | 80..BF | 80..BF |
| U+100000..U+10FFFF | F4 | 80..BF | 80..BF | 80..BFsource |
The table above shows the legal and valid UTF-8 byte sequences, as defined by the Unicode Standard 5.0. The lower ASCII range 00..7F has always been preserved in UTF-8. Multi-byte sequences start at code point U+0080 and continue from two to four bytes. For example, code point U+0700 would be encoded in UTF-8 as a two byte sequence, with the lead byte somewhere in the range of C2..DF.
Handling Ill-formed Byte Sequences
Over-consumption of well-formed byte sequences has been the vector for critical vulnerabilities. These generally expose widespread issues when they affect a widely used library. One example can be found in the Internationalization Components for Unicode (ICU) in 2009, which would leave almost any Web-application exposed to cross-site scripting (XSS) threats since software such as Apple’s Safari Web browser exposed the flaw. Even Web-applications with strong HTML/XSS filters can be vulnerable when the Web browser is non-conformant.
The following input illustrates the over-consumption attack vector, where an attacker controls the img element’s src attribute, followed by a text fragment in the HTML. The [0xC2] represents the attacker’s UTF-8 lead byte with an invalid trailing byte, the double quote “ which gets consumed in the resultant string. The HTML text portion including the onerror text is also attacker-controlled input. The entire payload becomes:
<img src=”#[0xC2]”> “ onerror=”alert(1)”</ br>
The resultant string after over-consumption:
<img src=”#> “ onerror=”alert(1)”</ br>
Although the above is a broken fragment of HTML because the img element is not properly closed, most browsers will render it as an img element with an onerror event handler.
Some of the common security vulnerabilities that exploit an over-consumption flaw as an attack vector include:
- Bypassing folder and file access filters.
- Bypassing parser-based filters such as HTML and XSS filters.
- Bypassing detection signatures in WAF and NID’s type devices.
As a developer trying to protect against this, it again becomes important to understand how the API’s being used will handle ill-formed byte sequences. The following table of common library API’s lists known behaviors:
| Library | API | Allows ill-formed UTF8 | Can override | Notes |
| .NET 2.0 | System.Text.Encoding | No | No | |
| .NET 3.0 | UTF8Encoding | No | No | |
| ICU | System.Text.Encoding | Yes | Yes |
As a tester/bug hunter looking for the vulnerabilities, the following table lists test cases to run from a black-box, external perspective. The data in this table presents byte sequences that could elicit over-consumption. You can substitute a % before each byte value to create a URL-encoded value for use in testing. This would be applicable for passing ill-formed byte sequences in a Web-application.
| Source bytes | Expected safe result | Desired unsafe result | Notes |
| C2 22 3C | 22 3C | 3C | Error handling of C2 overconsumed the trailing 22. |
| " | %C0%A2 | %E0%80%A2 | Double quote |
Over-consumption typically happens at a layer lower than most developers work at. It’s more likely to be in the frameworks, the browsers, the database, etc. If designing a character set or Unicode layer, be sure to include an error condition for cases where valid lead bytes are followed by invalid trailing bytes.
Handling the Unexpected
Through error handling, filtering, or other cases of input validation, problematic characters or raw bytes might be replaced or deleted. In these cases, it’s important that the resultant string or byte sequence does not introduce a vulnerability. This problem is not specific to Unicode by any means, and can occur with any character set. However as will be discussed, Unicode has a good solution.
Unexpected Inputs
TODO
Unassigned Code Points
U+2073
Illegal Code Points
e.g. half of a surrogate pair
Character Substitution
The following input illustrates a dangerous character substitution. In this case, the application uses input validation to detect when a string contains characters such as < and then sanitizes such character’s by replacing them with a . period, or full stop. Internally, the application fetches files from a file share in the form:
file://sharename/protected/user-01/files
By exploiting the character substitution logic, an attacker could perform directory traversal attacks on the application:
file://sharename/protected/user-01/../user-002/files
Character Deletion
An application may choose to delete characters when invalid, illegal, or unexpected data is encountered. This can also be problematic if not handled carefully. In general, it’s safer to replace with Unicode’s REPLACEMENT CHARACTER U+FFFD than it is to delete.
Consider a Web-browser that deletes certain special characters such as a mid-stream Unicode BOM when encountered in its HTML parsing. An attacker injects the following HTML which includes the Unicode BOM represented by U+FEFF. The existence of this character allows the attacker’s input to bypass the Web-application’s cross-site scripting filter, which rejects an occurrence of <script>.
<scr[U+FEFF]ipt>
The Unicode BOM has special meaning in the standard, and in most software. The following image illustrates some of the special properties associated with this character:
TODO add image
The Unicode BOM is recommend input for most software test cases, and can be especially useful when test text parsers such as HTML and XML.
Guidance
Handle error conditions securely by replacing with the Unicode REPACEMENT CHARACTER U+FFFD. If that’s impractical for some reason then choose a safe replacement that doesn’t have syntactical meaning in the protocol being used. Some common examples include ? and #.
Upper and Lower Casing
Strings are transformed through upper and lower casing operations, and sometimes in ways that weren’t intended. This behavior can be exploited if performed at the wrong time. For example, if a casing operation is performed anywhere in the stack after a security check, then a special character like U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE could be used to bypass a cross-site scripting filter.
toLower(“İ”) == “i”
Another aspect of casing operations is that the length of characters and strings can change, depending on the input. The following should never be assumed:
toLower(“scrİpt”) == “script”
Another aspect of casing operations is that the length of characters and strings can change, depending on the input. The following should never be assumed:
len(x) != len(toLower(x))
Common frameworks handle string comparison in different ways. The following table captures the behavior of classes intended for case-sensitive and case-insensitive string comparison.
| Library | API | Is Dangerous | Can override | Notes |
| .NET 1.0 | StringComparer | |||
| .NET 2.0 | StringComparer | |||
| .NET 3.0 | StringComparer | |||
| Win32 | CompareStringOrdinal | |||
| Win32 | lstrcmpi | |||
| Win32 | CompareStringEx | |||
| ICU C | ucol_strcoll | |||
| ICU C | ucol_strcollIter | Allows for comparing two strings that are supplied as character iterators (UCharIterator). This is useful when you need to compare differently encoded strings using strcoll | ||
| ICU C++ | Collator::Compare | |||
| ICU C | u_strCaseCompare | Compare two strings case-insensitively using full case folding. | ||
| ICU C | u_strcasecmp | Compare two strings case-insensitively using full case folding. | ||
| ICU C | u_strncasecmp | Compare two strings case-insensitively using full case folding. | ||
| ICU Java | caseCompare | Compare two strings case-insensitively using full case folding. | ||
| ICU Java | Collator.compare | |||
| POSIX | strcoll |
Buffer Overflows
Buffer overflows can occur through improper assumptions about characters versus bytes, and also about string sizes after casing and normalization operations.
Upper and Lower Casing
The following table from UTR 36 illustrates the maximum expansion factors for casing operations on the edge-case characters in Unicode. These inputs make excellent test cases.
| Operation | UTF | Factor | Sample | |
| Lower | 8 | 1.5 | Ⱥ | U+023A |
| 16, 32 | 1 | A | U+0041 | |
| Upper | 8, 16, 32 | 3 | ΐ | U+0390 |
source: Unicode Technical Report #36
Normalization
The following table from UTR 36 illustrates the maximum expansion factors for normalization operations on the edge case characters in Unicode. These inputs make excellent test cases.
| Operation | UTF | Factor | Sample | |
| NFC | 8 | 3X | 𝅘𝅥𝅮 | U+1D160 |
| 16, 32 | 3X | שּׁ | U+FB2C | |
| NFD | 8 | 3X | ΐ | U+0390 |
| 16, 32 | 4X | ᾂ | U+1F82 | |
| NFKC/NFKD | 8 | 11X | ﷺ | U+FDFA |
| 16, 32 | 18X |
source: Unicode Technical Report #36
Controlling Syntax
White space and line feeds affect syntax in parsers such as HTML, XML and javascript. By interpreting characters such as the ‘Ogham space mark’ and ‘Mongolian vowel separator’ as whitespace software can allow attacks through the system. This could give attackers control over the parser, and enable attacks that might bypass security filters. Several characters in Unicode are assigned the ‘white space’ category and also the ‘white space’ binary property. Depending on how software is designed, these characters may literally be treated as a space character U+0020.
For example, the following illustration shows the special white space properties associated with the U+180E MONGOLIAN VOWEL SEPARATOR character.
TODO: add image
If a Web browser interprets this character as white space U+0020, then the following HTML fragment would execute script:
<a href=#[U+180E]onclick=alert()>
Charset Mismatch
When software cannot accurately determine the character set of the text it is dealing with, then it must decide to either error or make an assumption. User-agents most commonly must deal with this problem, as they’re faced with interpreting data from a large assortment of character sets. There are no standards that define how to handle situations of character set mismatch, and vendor implementations vary greatly.
Consider the following diagram, in which a Web browser receives an HTTP response with an HTTP charset of ISO-8859-1 defined, and a meta tag charset of shift_jis defined in the HTML.
TODO add image
When an attacker can exploit can control charset declarations, they can control the software’s behavior and in some cases setup an attack.