Unicode Security Guide
1) Home Page
2) Background
Unicode Security Guide
Background
The Unicode Standard provides a unique number for every character, enabling disparate computing systems to exchange and interpret text in the same way.
Table of Contents
- History
- Introduction
- Character Encoding
- Character Escape Sequences and Entity References
- Security Testing Focus Areas
Brief History of Character Encodings
Early in computing history, it became widely clear that a standardized way to represent characters would provide many benefits. Around 1963, IBM standardized EBCDIC in its mainframes, about the same time that ASCII was standardized as a 7-bit character set. EBCDIC used an 8-bit encoding, and the unused eighth-bit in ASCII allowed OEM’s to apply the extra bit for their proprietary purposes. The following list roughly captures some of the history leading up to Unicode.
- 1991 - Unicode
- 1990 - ISO 10646 (UCS)
- 1985 - ISO-8859-1 (code pages galore!)
- 1981 - MBCS (e.g. GB2312)
- 1964 - EBCDIC (non-ASCII compatible)
- 1963 - ASCII 7-bit (an 8th bit free-for-all soon followed)
This allowed OEM’s to ship computers and later PC’s with customized character encodings specific to language or region. So computers could ship to Israel with a tweaked ASCII encoding set that supported Hebrew for example. The divergence in these customized character sets grew into a problem over time, as data interchange become error-prone if not impossible when computers didn’t share the same character set.
In response to this growth, the International Organization for Standardization (ISO) began developing the ISO-8859 set of character encoding standards in the early 1980’s. The ISO-8859 standards were aimed at providing a reliable system for data-interchange across computing systems. They provided support for many popular languages, but weren’t designed for high-quality typography which needed symbols such as ligatures.
In the late 1980’s Unicode was being designed, around the same time ISO recognized the need for a ubiquitous character encoding framework, what would later come to be called the Universal Character Set (UCS), or ISO 10646. Version 1.0 of the Unicode standard was released in 1991 at almost the same time as UCS was made public. Since that time, Unicode has become the de facto character encoding model, and has worked closely with ISO and UCS to ensure compatibility and similar goals.
Brief Introduction to Unicode
Most people are familiar with ASCII, it’s usefulness and it’s limitation to 128 characters. Unicode and UCS expanded the available array of characters by separating the concepts of code points and binary encodings.
The Unicode framework can presumably represent all of the worlds languages and scripts, past, present, and future. That’s because the current version 5.1 of the Unicode Standard has space for over 1 million code points. A code point is a unique value within the Unicode code-space. A single code point can represent a letter, a special control character (e.g. carriage return), a symbol, or even some other abstract thing.
Code Points
A code point is a 21-bit scalar value in the current version of Unicode, and is represented using the following type of reference where NNNN would be a hex value:
U+NNNN
The valid range for Unicode code points is currently U+0000 to U+10FFFF. This range can be expanded in the future if the Unicode Standard changes. The following image illustrates some of the properties or metadata that accompany a given code point.
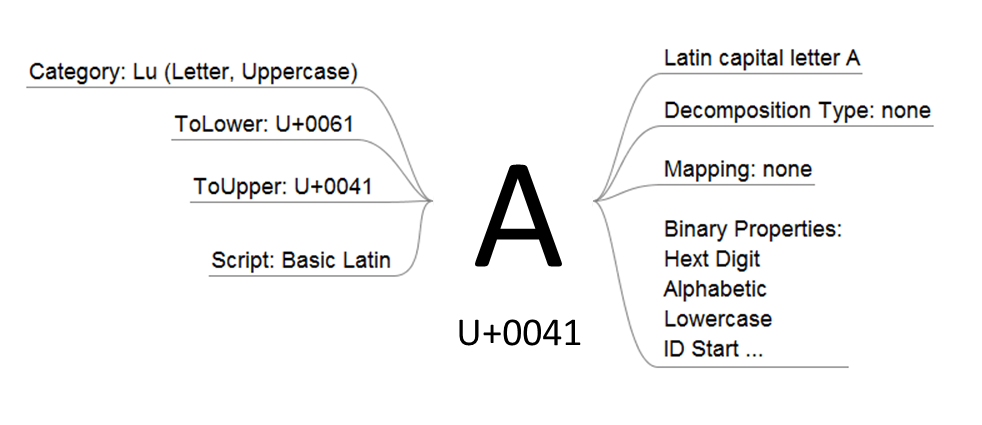
Code point U+0041 represents the Latin Capital Letter A. It’s no coincidence that this maps directly to ASCII’s value 0x41, as the Unicode Standard has always preserved the lower ASCII range to ensure widespread compatibility. Some interesting things to note here are the properties associated with this code point:
- Several categories are assigned including a general ‘category’ and a ‘script’ family.
- A ‘lower case’ mapping is defined.
- An ‘upper case’ mapping is defined.
- A ‘normalization’ mapping is defined.
- Binary properties are assigned.
This short list only represents some of the metadata attached to a code point, there can be much more information. In looking for security issues however, this short list provides a good starting point.
Character Encoding
A discussion of characters and strings can quickly dissolve into a soup of terminology, where many terms get mixed up and used inaccurately. This document will aim to avoid using all of the terminology, and may use some terms inaccurately according to the Unicode Consortium, with the goal of simplicity.
To put it simply, an encoding is the binary representation of some character. It’s ‘bits on the wire’ or ‘data at rest’ in some encoding scheme. The Unicode Consortium has defined four character encoding forms, the Unicode Transformation Formats (UTF):
- UTF-7 Defined by RFC 2152, and has since been largely deprecated and its use is not recommended.
- UTF-8 A variable-width encoding where each Unicode code point is assigned to an unsigned byte sequence of 1 to 4 bytes in length. Older versions of the specification allowed for up to 6 bytes in length but that is no longer the case.
- UTF-16 A variable-width encoding where each Unicode code point is assigned to an unsigned sequence of 2 or 4 bytes. The 2-byte sequences are comprised of surrogate pairs.
- UTF-32 A fixed-width encoding where each Unicode code point is assigned to an unsigned sequence of 4 bytes. UTF-32 employs a fixed mapping using the same numeric value as the code point, so no algorithms are needed.
Of these four, UTF-7 has been deprecated, UTF-8 is the most commonly used on the Web, and both UTF-16 and UTF-32 can be serialized in little or big endian format.
A character encoding as defined here means the actual bytes used to represent the data, or code point. So, a given code point U+0041 LATIN CAPITAL LETTER A can be encoded using the following bytes in each UTF form:
| UTF Format | Byte sequence |
| UTF-8 | < 41 > |
| UTF-16 Little Endian | < 41 00 > |
| UTF-16 Big Endian | < 00 41 > |
| UTF-32 Little Endian | < 41 00 00 00 > |
| UTF-32 Big Endian | < 00 00 00 41 > |
The lower ASCII character set is preserved by UTF-8 up through U+007F. The following table gives another example, using U+FEFF ZERO WIDTH NO-BREAK SPACE, also known as the Unicode Byte Order Mark.
| UTF Format | Byte sequence |
| UTF-8 | < EF BB BF > |
| UTF-16 Little Endian | < FF FE > |
| UTF-16 Big Endian | < FE FF > |
| UTF-32 Little Endian | < FF FE 00 00 > |
| UTF-32 Big Endian | < 00 00 FE FF > |
At this point UTF-8 uses three bytes to represent the code point. One may wonder at this point how a code point greater than U+FFFF would be represented in UTF-16. The answer lies in surrogate pairs, which use two double-byte sequences together. Consider the code point U+10FFFD PRIVATE USE CHARACTER-10FFFD in the following table.
| UTF Format | Byte sequence |
| UTF-8 | < F4 8F BF BD > |
| UTF-16 Little Endian | < FF DB > < FD DF > |
| UTF-16 Big Endian | < DB FF > < DF FD > |
| UTF-32 Little Endian | < FD FF 10 00 > |
| UTF-32 Big Endian | < 00 10 FF FD > |
Surrogate pairs combine two pairs in the reserved code point range U+D800 to U+DFFF, to be capable of representing all of Unicode’s code points in the 16 bit format. For this reason, UTF-16 is considered a variable-width encoding just as is UTF-8. UTF-32 however, is considered a fixed-width encoding.
Character Escape Sequences and Entity References
An alternative to encoding characters is representing them using a symbolic representation rather than a serialization of bytes. This is common in HTTP with URL-encoded data, and in HTML. In HTML, numerical character references (NCR) can be used in either a decimal or hexadecimal form that maps to a Unicode code point.
In fact, CSS (Cascading Style Sheets) and even JavaScript use escape sequences, as do most programming languages. The details of each protocol’s specification are outside the scope of this document, however examples will be used here for reference.
The following table lists the common escape sequences for U+0041 LATIN CAPITAL LETTER A.
| UTF Format | Character Reference or Escape Sequence |
| URL | %41 |
| NCR (decimal) | A |
| NCR (Hex) | A |
| CSS | \41 and \0041 |
| JavaScript | \x41 and \u0041 |
| Other | \u0041 |
The following table gives another example, using U+FEFF ZERO WIDTH NO-BREAK SPACE, also known as the Unicode Byte Order Mark.
| UTF Format | Character Reference or Escape Sequence |
| URL | %EF%BB%BF |
| NCR (decimal) |  |
| NCR (Hex) |  |
| CSS | \FEFF |
| JavaScript (as bytes) | \xEF\xBB\xBF |
| JavaScript (as reference) | \uFEFF |
| JSON | \uFEFF |
| Microsoft Internet Information Server (IIS) | %uFEFF |
Security Testing Focus Areas
This guide has been designed with two general areas in mind - one being to aid readers in setting goals for a software security assessment. Where possible, data has also been provided to assist software engineers in developing more security software. Information such as how framework API’s behave by default and when overridden is subject to change at any time.
Clearly, any protocol and standard can be subject to security vulnerabilities, examples include HTML, HTTP, TCP, DNS. Character encodings and the Unicode standard are also exposed to vulnerability. Sometimes vulnerabilities are related to a design-flaw in the standard, but more often they’re related to implementation in practice. Many of the phenomena discussed here are not vulnerabilities in the standard. Instead, the following general categories of vulnerability are most common in applications which are not built to anticipate and prevent the relevant attacks:
- Visual Spoofing
- Best-fit mappings
- Charset transcodings and character mappings
- Normalization
- Canonicalization of overlong UTF-8
- Over-consumption
- Character substitution
- Character deletion
- Casing
- Buffer overflows
- Controlling Syntax
- Charset mismatches
Consider the following image as an example. In the case of U+017F LATIN SMALL LETTER LONG S, the upper casing and normalization operations transform the character into a completely different value. Many characters such as this one have explicit mappings defined through the Unicode Standard, indicating what character (or sequences of characters) they should transform to through casing and normalization. Normalization is a defined process discussed later in this document. In some situations, this behavior could be exploited to create cross-site scripting or other attack scenarios.
The rest of this guide intends to explore each of these phenomena in more detail, as each relates to software vulnerability mitigation and testing.